我們在前一個範例中,成功辨識出不同的鹼基符號。然而,lex不僅僅能辨識字母,對於不同類型的詞彙模組也可以透過事先建立的規則來辨識喔!在這裡,我們要使用regular expression(中文翻譯為常規表示式)來撰寫規則。
Regular expression是一種利用符號來表示詞彙模組的敘述方式。下表列出了Regular expression所使用的符號。
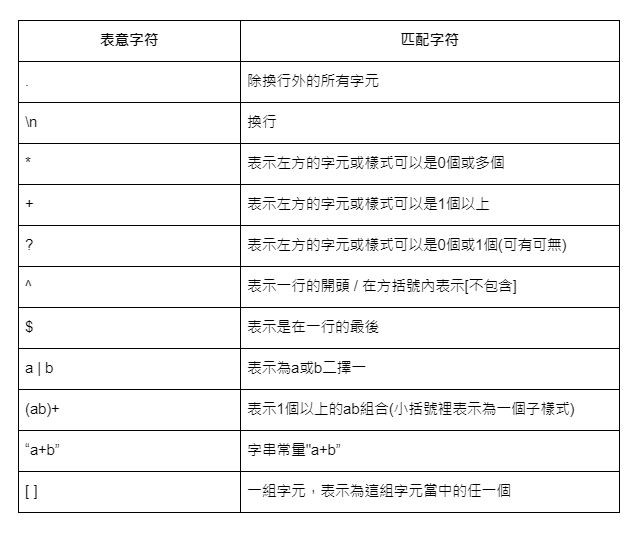
利用上列的表意字符,我們就可以表達出各種不同類型的字串組合。以下是一些表達式的例子,以及符合該表達式的字串。
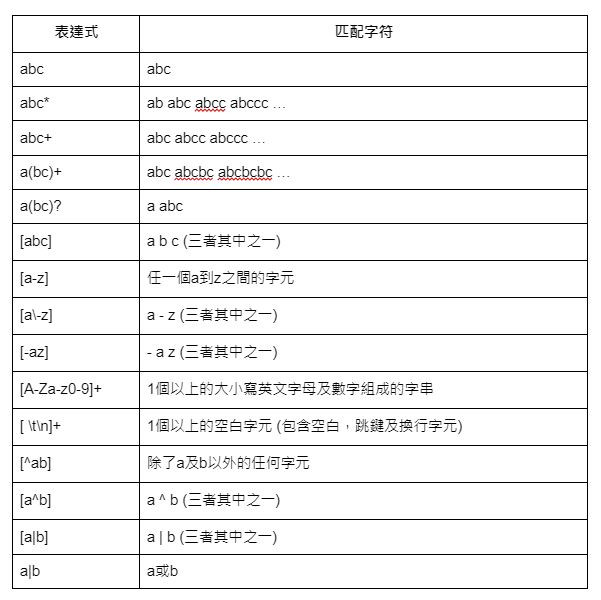
我們再來看一些常見的應用吧!可以試著自己遮住表達式寫寫看,再來對答案。
要注意的是,如果欲判斷的字元正好是特殊符號(如: * / \ ),可在前加上反斜線(),或是直接用雙引號來表示。

有了常規表示式,我們便可以自己定義需要的詞彙模式了。
給定一個字串,試著判斷其是否符合ID命名規範。
ID命名規範
- 變數中只能出現大小寫英文字母、數字與底線
- 變數的開頭不能是數字
我們在這裡可以事先定義合法ID的規則。
%{
%}
valid_id [_a-zA-Z][a-zA-Z0-9_]*
non_blank [^ \t\n]+
在前一個例子中,我們直接將規則寫在Rules區塊。然而,當regular expression的規則越趨複雜時,我們可以把它包成一個規則變數,並定義在Definitions區塊中,寫法如上。要注意的是,變數名稱與regular expression要有至少一個空白區隔。據此,我們將合法ID的規則命名成valid_id,且將所有不含空白的字串命名為non_blank。
當我們讀取到字串的時候,先檢查是否符合ID命名規範。
若符合,則印出”符合”的相關訊息。
若不符合,則印出”不符合”相關訊息。
%%
{valid_id} { printf("Valid Identifier: %s\n", yytext); }
{non_blank} { printf("Invalid Identifier: %s\n", yytext); }
\n { ; }
. { ; }
在這裡,我們就可以直接引用regular expression的變數了。
使用變數時,要使用大括號包起來,避免被lex當成是字串。
在這裡,我們發現了一項新玩意:yytext。
yytext是lex中的預設變數,它是一個char pointer,指向目前讀取到的文字。
因此,我們可以直接利用 printf 來印出讀取到的字串。
不過,這樣的寫法其實會出現一個問題:當出現了一個合法ID,同時符合{valid_id}與{non_blank}這兩個條件,lex要怎麼判斷呢?
答案很簡單:lex會以從上到下的方式比對,因此合法ID的規則會先被valid_id配對成功,不會匹配到non_blank。
%{
%}
valid_id [_a-zA-Z][a-zA-Z0-9_]*
non_blank [^ \t\n]+
%%
{valid_id} { printf("Valid Identifier: %s\n", yytext); }
{non_blank} { printf("Invalid Identifier: %s\n", yytext); }
\n { ; }
. { ; }
%%
int yywrap(void) {
return 1;
}
int main(void) {
const char* sFile = "file.txt";
FILE* fp = fopen(sFile, "r");
if (fp == NULL) {
printf("cannot open %s\n", sFile);
return -1;
}
yyin = fp;
yylex();
return 0;
}
gfg
123
_abc12
#abc
ancvi##agh
Valid Identifier: gfg
Invalid Identifier: 123
Valid Identifier: _abc12
Invalid Identifier: #abc
Invalid Identifier: ancvi##agh
今天介紹了Regular Expression,可以幫助我們制定更複雜的配對規則,做到更廣泛的讀檔需求。
本文也介紹了yytext這個指標,它指向了目前讀取到的文字,以供我們使用。

